
Turnback: A Lazy Engineer's Approach to Multi-turn Attribution
The last 10% is finding the broken turn, not fixing it

There is a quote that gets passed around in engineering circles, that you should always give a hard job to a lazy person because a lazy person will find an easy way to do it. I have been using this as personal justification for years, and the library I built last month is the most honest proof of that theory I have produced so far. Also, what else is there to do when your Claude is “Flibbertigibbeting”(or any other exactly 186 ings)?!
I was reviewing failed conversation traces from a customer support chatbot I built for a friend’s Shopify store, for the millionth time. This is one of those tasks that sounds like 15 minutes and takes an hour, every time, because there is always another one. You open the trace, read all 10 turns, find the moment where the model went sideways by eye, extract the prefix, write the regression test, close the tab, and then the next failed trace appears, and then the next. I’m exhausted just typing that out. The work is not hard but it is just tedious enough that I eventually started asking whether it had to be this tedious…which is where lazy engineering begins, also known as “how fast can I automate this thing”. The sheer dread of opening failed traces is a developer experience problem, and it seemed more solvable than it looked.

The standard technique for testing multi-turn conversations is called N+1 evaluation which is when you take a conversation prefix up to turn N, feed it to the model, score what it says at turn N+1. This works well once you know which turn N to test. The problem is figuring out which turn N to test in the first place.
The way most people do it, myself included for an embarrassingly long time, is to read the full trace, find where things went wrong by eye, and extract that prefix manually. That step grinds you down at scale, and the deeper issue is that the turn you identify by eye is usually the turn where the failure surfaced rather than the turn that caused it. The trace I will walk through here is a simplified version of the kind of scenario that kept appearing in my chatbot logs. A customer asks at turn 2 whether a specific item is in stock, the assistant at turn 3 confirms it is available without actually querying the inventory feed, and then spends the next 11 turns trying to walk back a promise it had no business making. The conversation fails at turn 14 but the cause was turn 3, and every regression test I wrote targeting the end of that conversation was testing the symptom, not the disease. I was building an eval suite that felt comprehensive and was systematically covering the wrong thing.
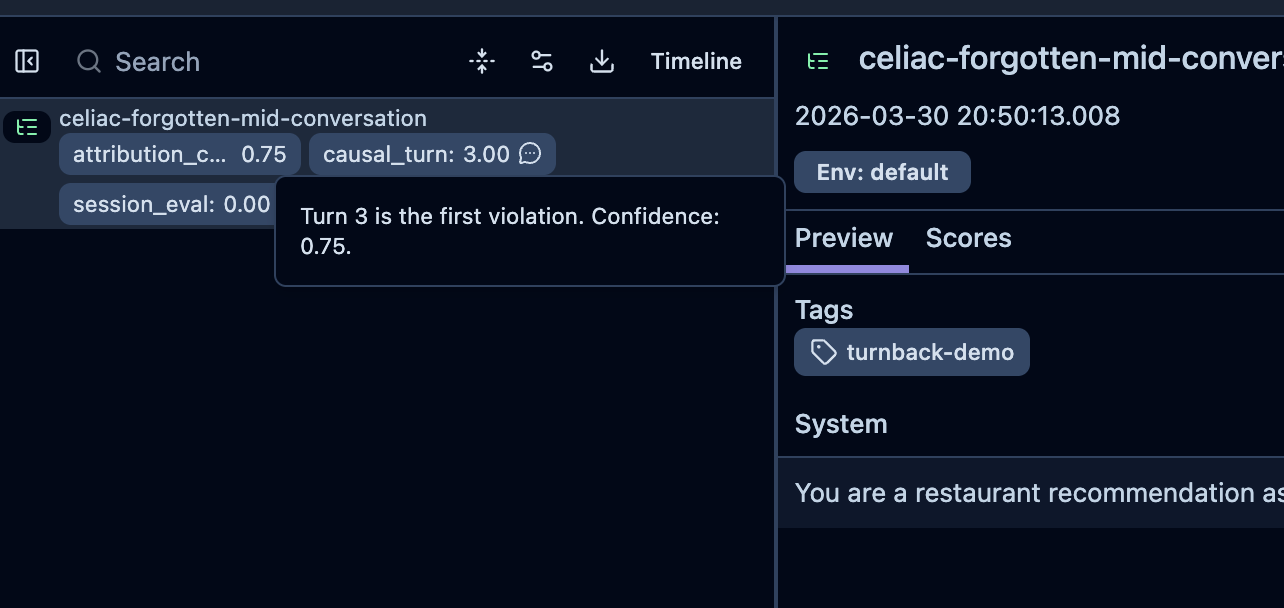
So I built a small library to help with this. I am calling it turnback, and given a failed conversation trace and a session-level evaluator, it uses a linear scan to find the earliest turn where a specific response violated an established constraint. To be clear about what this is and is not: N+1 evaluation is how you test a conversation once you know which turn to test. Turnback is how you find that turn in the first place. It does not replace the eval step, it feeds it. It does not make the attribution decision for you. I run it inside Langfuse [a tool for tracing and evaluating LLM applications] where it surfaces 1 or 2 candidate turns with a confidence score and stops, leaving a human(me) to confirm. Instead of reading 10 turns, I am reading 2, which is the lazy engineer’s way of not avoiding the judgment but automating the search. (And yes, the judgment still has to happen. Annotation is not a one-time thing. Whether you are writing regression tests, keeping an LLM-as-judge calibrated, or just staying honest about where your chatbot is failing, someone has to keep looking at the traces. Turnback just makes that person dread it a little less. )
The core loop looks like this:
from turnback import attribute
result = attribute(
trace=failed_messages, # list[dict] in OpenAI/Langfuse format
evaluator=my_evaluator, # (Trace) -> EvaluatorResult
turn_constraint=( # what counts as a violation at the turn level
"Flag any response that makes a concrete claim about inventory "
"without confirming it against the live feed."
),
api_key="...", # or ANTHROPIC_API_KEY env var
)
# result.candidate_turns -> [3]
# result.confidence -> {3: 0.75}
# result.systemic_failure -> FalseFor each assistant turn M, excluding the last which is the known symptom, the library asks one question: did this response violate the constraint given what the model already knew? Not “would fixing this turn have led to a passing conversation?” That question requires a simulator. This one just requires the prefix and a judgment. The scan proceeds from earliest to latest and stops at the first confirmed violation. The estimated call count for a 10-turn trace is 1 to 4 claude-haiku-4-5-20251001 calls at temperature 0.0, deterministic, cheap, fast.
Note about the name choice - The first name was ‘traceback’, which lasted about 5 minutes until I ran the import and watched Python silently resolve it to the stdlib traceback module instead of mine. Naming things is hard and then sometimes Python makes it harder.
I did not start here. My first design had three components: a rewriter, a user simulator, and a session evaluator scoring the replayed conversation. It seemed obviously correct. Then I ran it:/
The three things I had to learn the hard way
Coverage fingerprinting ended up mattering more than I expected. Every time I confirmed a causal turn and extracted a prefix as a regression test, I was adding slight variations of failures I had already covered. The same constraint-drop failure with different products, different conversation lengths, looking distinct but testing the same underlying pattern. 100 test cases covering 12 patterns is not the same as 100 test cases covering 100 patterns. The library checks cosine similarity against existing cases before anything new goes in and tracks distinct coverage clusters alongside raw test case count. It is the one thing I have not seen anywhere else in eval tooling so obviously solving this became a mission goal.
LLM simulators are more cooperative than real users. A real user who got a wrong answer at turn 4 might abandon the task entirely. The simulated user would politely re-introduce the constraint and try again, which meant any rewrite of any early turn tended to produce a passing conversation regardless of whether it addressed anything real. Binary search was confidently returning turn 1 on nearly every trace. Switching to the narrower question of “did this turn break the rule” removed two components from the pipeline and produced better results than the three-component version ever did.
Confidence scores are ordinal until you calibrate them. The raw score is a position weight i.e. earlier violations get higher confidence because the root cause is more likely to be an early constraint drop than a late symptom. An uncalibrated 0.85 on my traces mapped to roughly 70% accuracy once I validated it, which is a meaningful difference in how aggressively you act on the result. The library has a validate() function that runs against traces where you already know the ground truth, and a calibrate() function that fits an isotonic regression curve mapping raw scores to empirically grounded ones. Until you run those, treat the float as a rank and not a probability. On the calibration work itself, the 40 traces I labeled are not part of the normal workflow. They are a one-time benchmark batch. I labeled them manually to get clean ground truth, ran the library against the same traces to check agreement, and stopped labeling once the scores were calibrated. The point of calibration is to earn the right to stop doing that work, not to add it permanently.
I’m pretty pleased with the time(and sanity) saving so far. The review that used to take several minutes on a long trace takes under a minute, and because it lives in the same view I was already looking at, I actually look at it! The scan has a specific shape it is good at. Two patterns fall outside what the scan handles well. The first is gradual drift, where small overclaims compound across turns and no single response is a clean violation. The scan returns systemic_failure=True with no causal turn. What helps here is what I call intent snapshots. Every N turns, have the model produce a one-sentence summary of what the user is trying to accomplish and diff them across the conversation. If the intent summary at turn 6 no longer matches turn 2, that is worth flagging before your session evaluator catches it. Turnback finds the turn where a constraint was broken, intent snapshots surface the turns where the model quietly lost the thread. The second is no-future-context borderline misses. The turn evaluator sees only the prefix and the turn in question, not what comes after. A response that looks fine in isolation but contributes to a downstream failure may be scored clean. When in doubt, check the search_log and review the surrounding turns manually.
🛠️ Behind the Build
I looked at Braintrust and LangSmith’s experiment runners before building anything and both are solid for running your chatbot against a fixed prefix, but neither helps with identifying which prefix to test in the first place, which was the step consuming most of my time. The linear scan and turn evaluator took about a day to build cleanly once I had abandoned the simulation approach. The Langfuse webhook integration took an afternoon and is about 80 lines of Python: a FastAPI endpoint that fires whenever a trace scores FAIL, calls async_attribute() in the background, and writes two scores back to the trace, causal_turn and attribution_confidence. When I open a failed trace now those scores appear inline alongside session_eval: FAIL, I click through to the candidate turn, confirm it, and close the tab. Coverage fingerprinting uses TF-IDF by default with no external API needed, built on scikit-learn, with an optional Voyage AI backend for better semantic quality on production volumes. The stack underneath is Python 3.11, pgvector for retrieval, and a session evaluator calling claude-sonnet-4-6 with a rubric across four failure dimensions.
The repo is on GitHub at [https://github.com/nehasriva/turnback]. If you have a RAG chatbot with a working session evaluator and a backlog of failed traces you keep meaning to get to, clone it and give it a shot. The README covers the evaluator prompt in full, the calibration workflow, and the failure taxonomy in more detail than I have here.
The last 10% formula for multi-turn evaluation is a mature session evaluator plus a way to search backward through a failed trace plus a human who confirms. The first and the last have always been there. The middle part is what I was missing and what I ended up building. It does not close the gap entirely but it makes it navigable.
trace_review_cost = (manual_reads × turns_per_trace) / lazy_engineer_index